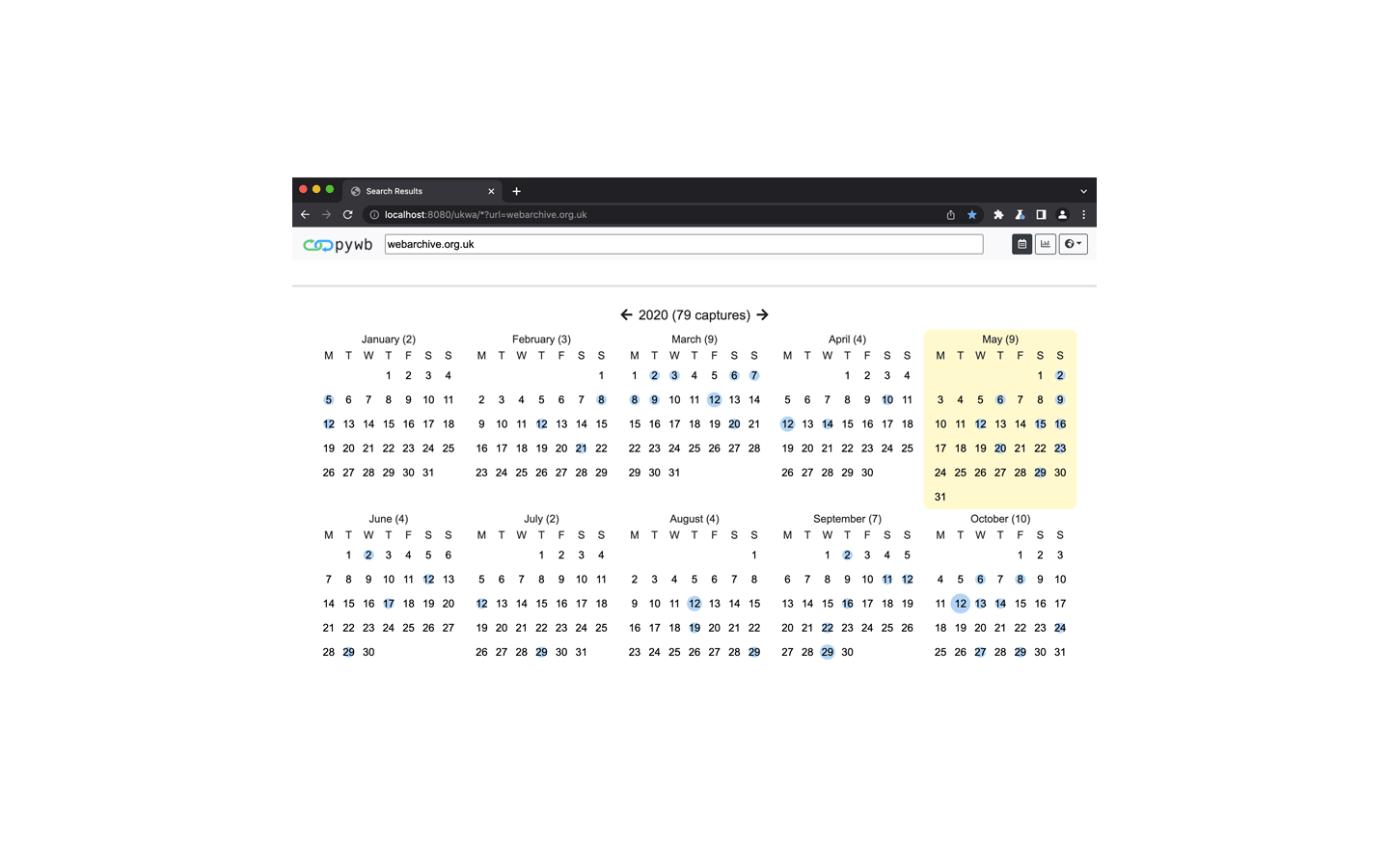
Hosting
We run a stack of equiptment which is mostly storage on enterprise grade server equiptment. We're looking to find a permament home for our stack.
 tkrn's archive
tkrn's archive... mission is a niche web archive specifically focused on the preservation of vintage computer technology, video game console and rf related information. There is an emphasis on preserving sites that have are focused on the reverse engineering of hardware and software componets in addition of bulk binary based (driver/game/mod/code) repositories.
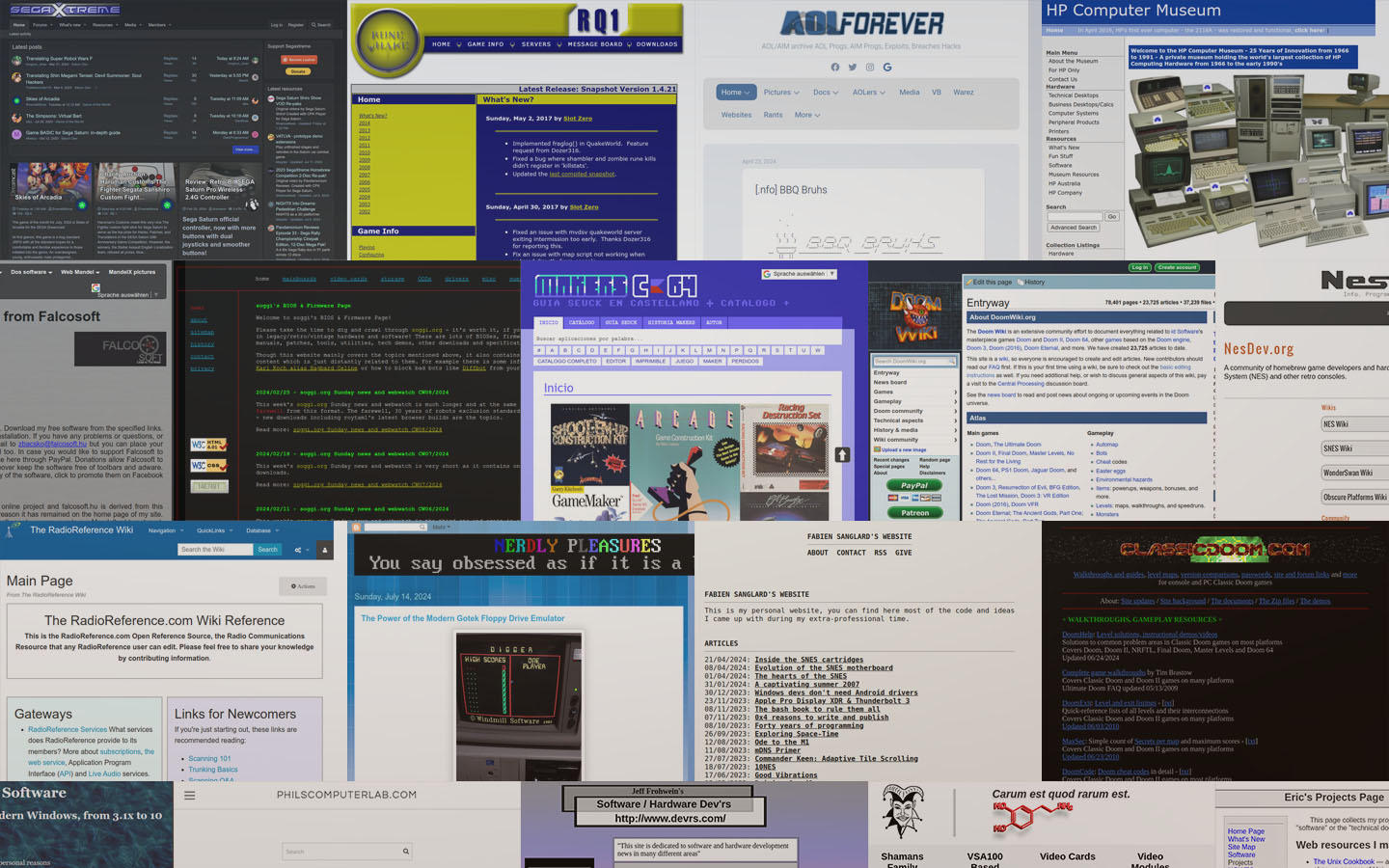
tkrn's archive is different because crawls include all crawlable binary links. Generally, speaking other crawls may contain the html contents but not binary files (ie. exe, zip) that is linked from the orginal page. tkrn's archive emphesis is to capture binary related web material that is linked.
We're a focused web crawler built that is meant to preserve aging information which is very literally disspearing at an alarming rate. We're focused on the primary areas:
We target to preserve self hosted code repositories regardless of subversioning technologies.
We look to preserve aged documentation, code examples, diagrams, schematics and anything electronic related.
We look to preserve HAM and RF related technologies. This includes but not limited to HAM, broadcast technologies, satellite and Bluetooth.
We look to preserve game consoles, tv consoles, handhelds, and standalone cabinets.
We look to preserve personal computer history from the early days of Heath kits all the way through the early 2010s. In addition, we preserve server based technologies in the same time period.
We look to preserve FTP sites that have gone dormant and run the risk of being pulled down that matches one of the other criteria.
This passion of ours has been fueled out of our heart and desire with the means that we have accessible to us at this point in time. If you feel similar to us and want to support our mission please find a way that you can contribue.
We run a stack of equiptment which is mostly storage on enterprise grade server equiptment. We're looking to find a permament home for our stack.
We haven't been to every nook and cranny of the internet. If you have websites that fit the archive criteria please share them before that data is lost forever!

Do you have access to enterprise hardware? We leverage hardware that has been lifecycled out of datacenter. We are seeking compute and storage. Hardware donations are welcomed!

Not sure how to help? We accept PayPal and Eth donations that will be used for our operational costs.
This passion of ours has been fueled out of our heart and desire with the means that we have accessible to us at this point in time. If you feel connected to our mission and want to support our mission please find a way that you can contribue. We can't do this alone. We need your help. Thank you.
We are in the process of transitioning from OpenWayback to pywb for the replaying and presentation of tkrn's archive repository. It is our plan and hope once we find a permament home that we'll be able to open the archive for public use.